Coursera - Bayesian Methods for Machine Learning
Think Bayesian & Statistics Review
Basic Principle
어떤 사람이 공원에서 달리는 것을 보았다.

가장 타당한 설명은 무엇인가?
Principle 1: Use prior knowledge
드래곤은 존재하지 않는다는 것을 안다. 4번 제외
Principle 2: Choose answer that explains observations the most
스포츠 수트를 입고있지 않으므로 2번은 아니다.
Principle 3: Avoiding making extra assumptions
세번째는 추가적인 가정이 들어갔으므로 제거해야한다.
Occam’s Razor
이 원칙들은 오캄의 면도날이라고 한다.
Review of probability
확률
확률변수
이산, 연속 : PMF, PDF
독립
조건부 확률
\(P(X\)|\(Y)=\frac{P(X,Y)}{P(Y)}\)
\[\text{Conditional} = \frac{\text{Joint}}{\text{Marginal}}\]Chain rule
\(P(X,Y)=P(X\)|\(Y)P(Y)\)
\(P(X,Y,Z)=P(X\)|\(Y,Z)P(Y\)|\(Z)P(Z)\)
Sum rule
\[p(X)=\int_{-\infty}^{\infty}p(X,Y)dY\]위는 Marginalization하는것
Bayes theorem
\(\theta\) - parameters
\(X\) - observations
| \(P(\theta\)|$$X)=\frac{P(X,\theta)}{P(X)}=\freac{P(X | \theta)P(\theta)}{P(X)}$$ |
좌변은 Posterior
우변은 각각 Likelihood와 Prior
분모는 Evidence
Bayesian approach to statistics
Uncertainty interpretation
Frequentists는 대상을 objective하게 여기고,
Bayesians는 대상을 subjective하게 여긴다.
Frequentists는 코인이 던져지면 어쩔 수 없이 50대 50확률로 앞 뒤가 나올것이라고 생각한다.
Bayesians는 초기 조건, 동전이 던져지는 속도 등에 따라 확률을 알 수 있을 것이라고 생각한다.
Data and parameters
Frequentist는 \(\theta\)는 고정되어있고 \(X\)가 랜덤이라고 생각한다. 그래서 optimal point를 찾고싶어 한다.
Bayesian은 \(\theta\)가 랜덤이고 \(X\)는 고정되어있다고 생각한다. 이는 어떤 모델을 학습시키려고 할 때 데이터는 이미 가지고 있고, 그 데이터는 고정이기 때문에 말이 된다.
| Frequentist는 $$\left | X \right | > > \left | \theata \right | $$ 일때만 가능. 데이터가 파라미터보다 훨씬 많을 때. |
Bayesian은 어떠한 갯수의 데이터라도 가능.
Training
Frequentist는 Maximum Likelihood Principle에 따라 학습한다.
\(\hat{\theta}=argmax_{\theta}P(X\)|\(\theta)\)
파라미터가 주어졌을 때 데이터가 나올 수 있는 확률을 최대화하는 파라미터를 찾으려고 한다.
Bayesian는 posterior를 계산한다.
| \(P(\theta\)|$$X)=\frac{P(X | \theta)P(\theta)}{P(X)}$$ |
이들은 데이터가 주어졌을 때 파라미터의 확률을 계산한다. 이 때 Bayes 공식을 활용한다.
Classification

tr은 training
ts는 test
Regularization
prior를 Regularizer로 여길 수 있다.

동전 앞면이 나올 확률을 계산한다고 하면, bias에 따라 prior의 distribution을 다르게 설정할 수 있다.
fair하다고 생각하면 0.5 주위로 종모양의 distribution
unfair하다고 생각하면 head쪽에 조금 더 높은 종모양.
On-line learning
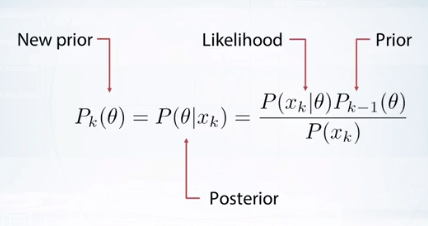
posterior를 계산한 것을 바탕으로 새로운 prior를 다시 학습에 이용할 수 있다.
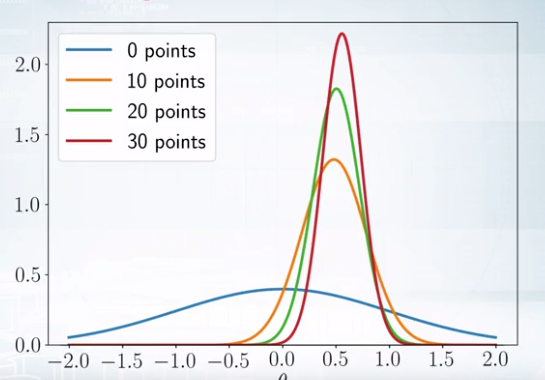
점점 성능이 좋아지고 variance가 줄어든다.
Probabilistic Model
Bayesian network
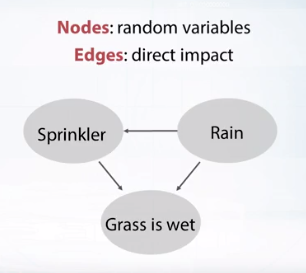
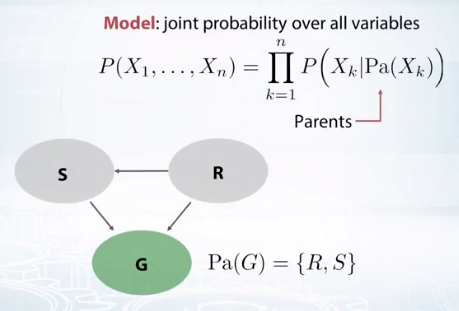
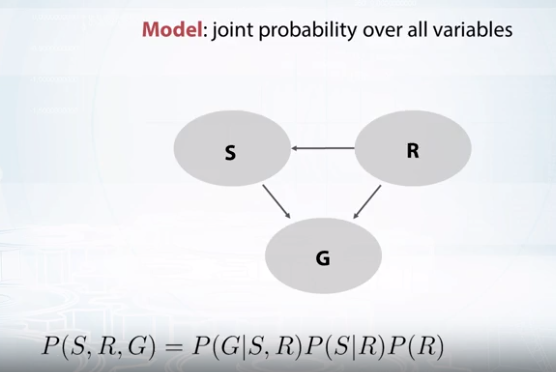
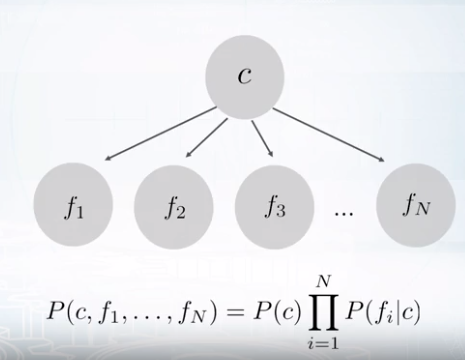
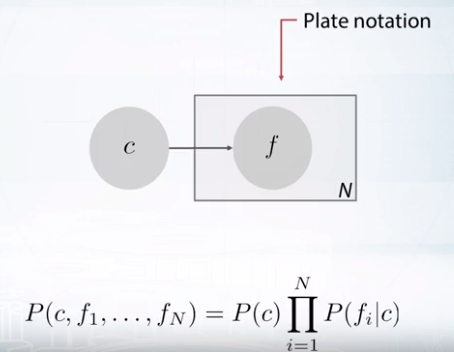
사이클이 있는 경우는
MRF
https://en.wikipedia.org/wiki/Markov_random_field
이렇게 그래프로 표시하는 모델을 Graphical Model이라고 하는데 랜덤변수간의 의존도를 직관적으로 보여준다.