Analytical Inference
베이지안에서 분모의 evidence를 모델링하는건 쉬운 일이 아니다.
반 고흐의 그림을 모델링 할 수 있겠는가?
Maximum a posteriori
Evidence의 계산을 우회하기 위한 방법이 MAP이다.
\(\theta_{MP}=argmax_{\theta} P(\theta\)|\(X)\)
\[\theta_{MP}=argmax_{\theta} \frac{P(X|\theta)P(\theta)}{P(X)}\] \[\theta_{MP}=argmax_{\theta} P(X|\theta)P(\theta)\]Evidence는 \(\theta\)와 independent하기 때문에 없애줘도 된다.
MAP: problems
그러나 MAP는 많은 문제가 있다.
가장 큰 묹는 MAP가 reparametrization에 대해 invariant하다는 것이다.
예를들어 Gaussian Distribution \(P_x\)
Sigmoid function \(f(x)\)
이 있다고 할 때, \(P_{f(x)}\)는 maximum point가 변경된다.
이는 정말 큰 문제다.
다음 문제는 prior를 사용할 수 없다는 것이다.
MAP를 다음 예측의 prior로 사용하려고 하면
\[P_k (\theta) = \frac{P(x_k|\theta)P_{k-1}(\theta)}{P(x_k)}\] \[P_k (\theta) = \frac{P(x_k|\theta) \delta(\theta - \theta_{MP})}{P(x_k)}= \delta(\theta- \theta_{MP})\]또 다시 MAP estimation의 delta function을 얻게 된다.
어떠한 새로운 정보도 얻을 수 없다.
또 다른 문제는 MAP가 untypical point라는 것이다. 주변에 충분한 확률밀도가 없기 때문에.
\[L(\theta) = I[\theta \ne \theta^*] \rightarrow min_{\theta}\]ideal value에서 끝냈는지에 대해 Indicator로 쓰일 수 있다.
우리는 다른 objective function을 이용할 수 있다.

mean은 평균, median은 중앙값, mode는 최빈값.
이를 통해 어떤 값을 얻을지를 설정할 수 있다.
마지막으로 credible equation을 계산할 수 없다.

Summary
Pros
- Easy to compute
Cons
- Not invariant to reparametrization
- Can’t use as a prior
- Finds untypical point
- Can’t compute credible intervals
Conjugate distributions
Evidence 계산을 피하는 또 다른 방법은?
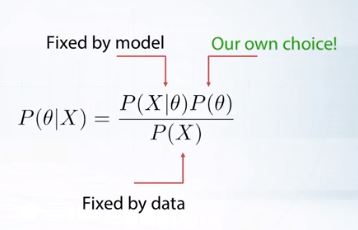
Likelihood는 model에 의해, Evidence는 data에 의해 고정되어있다.
우리가 선택할 수 있는 것은 prior다.
이 선택을 통해 posterior를 쉽게 선택할 수 있도록 해보자.
prior는 likelihood의 conjugate로 알려져있다.

prior와 posterior가 같은 종류의 distribution이면,
예를들어 prior가 어떤 평균과 분산의 정규분포라면 posterior도 어떤 다른 평균과 분산의 정규분포로 여긴다.

likelihood가 정규분포라면?
conjugate prior는? 만약 정규분포를 선택한다면?
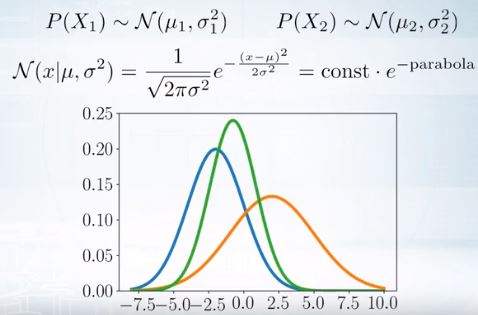
둘을 곱해서 하나의 통합된 방식으로 리메이크하면 어떨까?
다시 정규분포가된다.(파랑과 오렌지 곱해서 초록이됨)
정규분포는 exponential 함수라서 곱하면 모양이 합쳐진다.
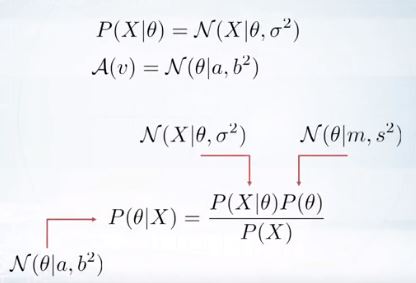
a와 b로 파라미터화되어 posterior가 생성된다.
Example
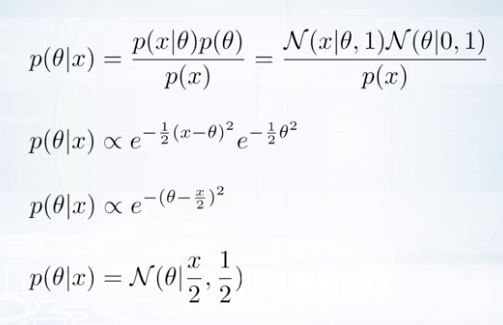
Likelihood의 평균이 \(\theta\)면 conjugate.
Example: Gamma, Normal, precision
Distributions: Gamma
두개의 파라미터에 의해 parameterized된다.
\[\Gamma(\gamma | a,b) = \frac{b^a}{\Gamma(a)}\gamma^{a-1}e^{-b \gamma}\]여기서 \(\gamma, a, b, \gt 0\) 모두 양수!
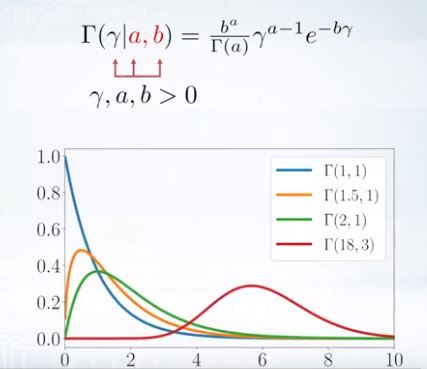
modal 분포이거나 지수함수모양이 된다.
첫번째 항은 함수를 증가시키고 두번째 항은 함수를 감소시킨다.
a가 정수라면 계수의 분모의 감마는 팩토리얼이된다.
\[\Gamma (n) = (n-1)!\]
Example
달리기를 모델링해보자.
정규분포로 모델링해도 되지만, 음수의 거리가 나올 확률이 있기 때문에 좋지 않다.
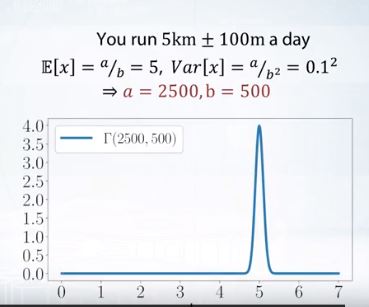
감마는 포아송과정의 연속확률버전..
달리는 속도 자체는 일정하지 않지만 어느정도의 평균 rate를 가진다.
Example: Normal, precision
감마분포는 정밀도에 따라 정규분포의 conjugate가 되기도 한다.
precision
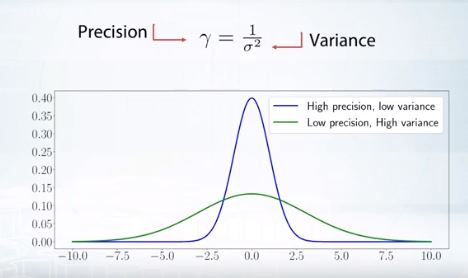
variance 제곱에 반비례한다.
예를들어 정규분포의 variance를 다음처럼 precision으로 교체할 수 있다.
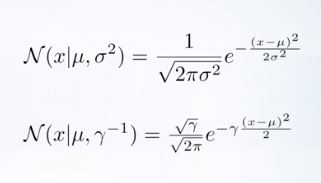
그럼 이제 정밀함에 대한 conjugate prior는 무엇일까.
gamma와 independent한것을 모두 삭제하면 다음과 같다.
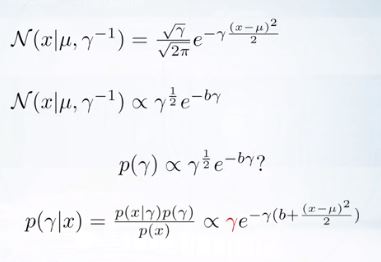
이제 conjugate를 감마 1/2승에 비례하는 것이라고 여기면 어떨까.
posterior에 대해 감마는 제곱이 없이 1차로 비례한다.

그래서 이는 틀렸다.
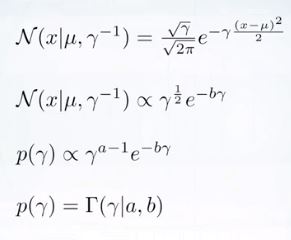
그러나 이처럼 설정하면?
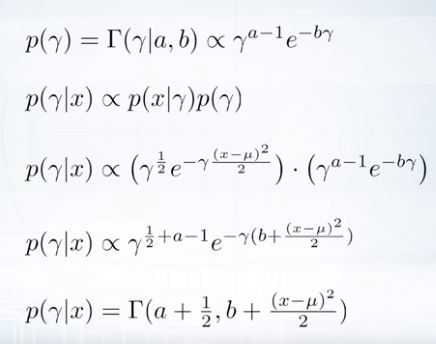
이 형식에서 우리는 posterior에 대한 parameter를 예측할 수 있다.
mean은 a+1/2, 그리고 variance는 b+sum of quadratic term.
이렇게 우리는 conjugate prior를 통해 evidence를 계산하는 것을 우회했다.
Example: Bernoulli
Beta distribution
베타 분포는 정해진 범위를 가진 확률변수 x를 모델링하는 것에 매우 유용하다.
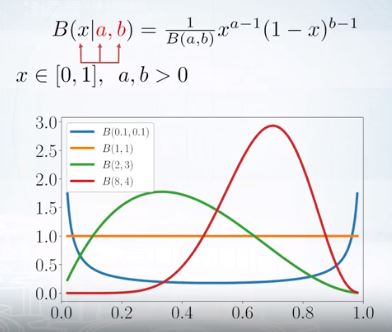
modal이거나 U-shape이거나, uniform이거나.
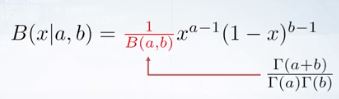
Normalization constant는 위와같다. 베타분포는 감마 분포 사이의 비율로 나타낼 수 있다.
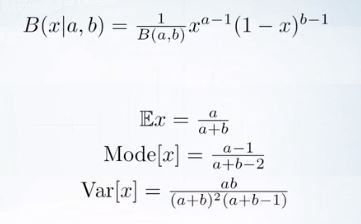
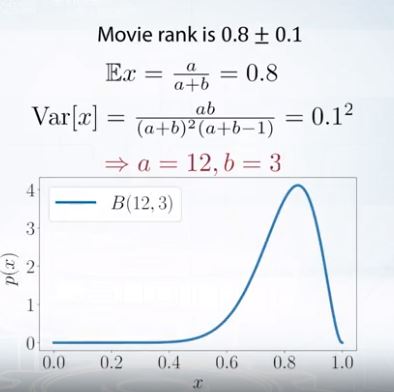
Example: Movie rank
웹사이트에서 영화 순위를 매긴다고 할 때, 0~1점 사이로 매긴다고 하자.
평균 0.8이고 분산이 0.1이라고 할 때 분포는 다음과 같이 모델링할 수 있다.
Bernoulli
베타분포는 사실 베르누이 likeliood의 conjugate이다.
0, 1 둘중에 하나인 데이터셋이 있다.
\(N_1\)은 X에 등장한 1의 갯수,
\(N_2\)는 X에 등장한 0의 갯수.
prior를 베타분포로 설정하면 constant가 떨어져나간다.
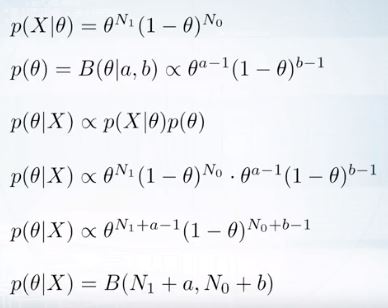
Summary
posterior를 계산하고 싶지만 evidence때문에 계산할 수가 없다.
이를 계산하기 위해 prior를 계산하기 쉬운 분포로 정한다.
이를 위해 conjugate prior를 이용함.
Pros
- Exact posterior
- Easy for on-line learning
Cons
- Conjugate prior may be inadequate for some models