Latent Variable Models
Latent variable이란 training이나 test에서 관찰 불가능한 숨겨진 변수를 의미한다.
길이나 높이같은것은 측정할 수 있지만 그렇지 못한것도 많다.
이러한 누락된 값이 존재하고, 그 불확실성을 정량화하기 위해 데이터의 probabilistic model을 필요로한다.
확률모델을 만들 때 어떤 확률변수가 다른 확률변수에 어떤 상관관계를 맺는지를 생각해야 한다.
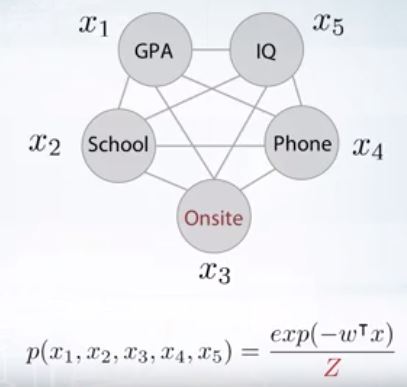
이와같이 모든 확률변수가 서로 연관이 있다고 해보자. 이와같이 선형함수를 지수로 하는 것을 정규화상수를 나누는 식으로 모델링하면 복잡도가 낮아진다. 그러나 정규화상수를 계산하는것이 쉽지 않다.
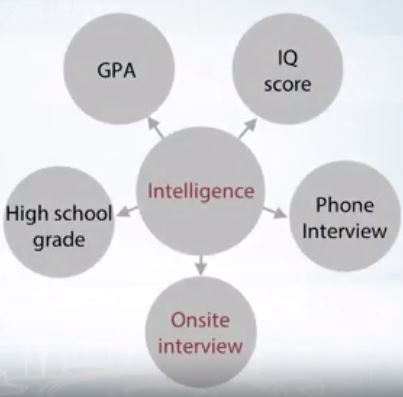
우리는 ‘지능’과 같은 숨겨진 변수를 집어넣을 수 있다.
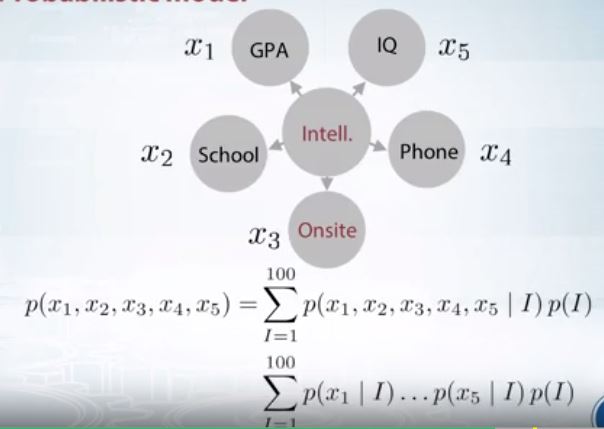
이러한 방식으로 우리는 유연성을 줄이지 않고 모델할 수 있게 된다.
Pros
- Simpler models(less edges)
- Fewer parameters
- Latent variables are sometimes meaningful
Cons
- Harder to work with
Probabilistic clustering
Hard clustering. 여기 속하는 거 아니면 다른 곳에 속함.
Soft clustering. 여기 몇 % 정도 속하고, 저기 몇 %정도 속하고.. 어떤 특정한 클러스터에 속하는 것이 아니라 모든 곳에 속하지만 정도의 차이가 있을 뿐.
\(p(\)cluster idx | \(x)\)
indstead of
cluster idx=\(f(x)\)
이렇게 하는 이유는?
먼저 missing data를 자연스럽게 다룰 수 있기 때문이다.
다음으로 clustering을 확률적으로 다룸으로써 hyperparemeter를 튜닝할 수 있다.
training set에서는 cluster의 수를 올릴수록 좋지만, validation set에서는 어떤 적정한 지점 이후로는 점점 log likelihood가 떨어진다.
이런건 hard clustering에서는 불가능하다.
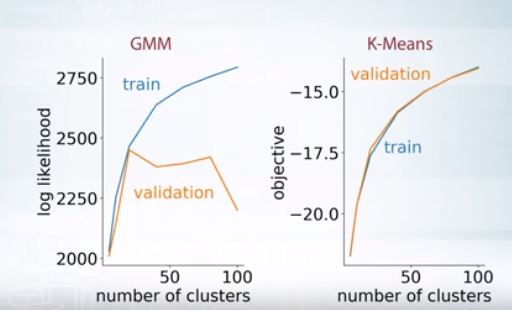
k-means의 경우 training set과 validation set 모두에서 cluster의 수가 늘어날 수록 loss도 줄어들어서 의미가 없다.
그리고 우리는 data의 generative model을 만들 수 있다.
Summary
- Allows to tune hyper parameters
- Generative model of the data
Gaussian Mixture Model
데이터를 확률적으로 모델링하기 위해서는 가우시안을 활용할 수 있다.
그러나 하나의 가우시안으로 모든 것을 모델링하기에는 적합하지 않다.
여러개로 나누면 가능하다.
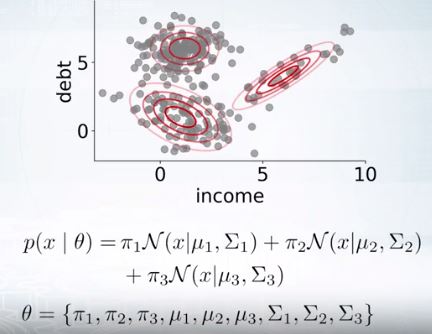

Training GMM
GMM을 학습하기 위해선 다음을 최적화한다.
\[max_{\theta} p(X|\theta) = \prod_{i=1}^{N}p(x_i | \theta)\]가우시안 여러개를 합친것.
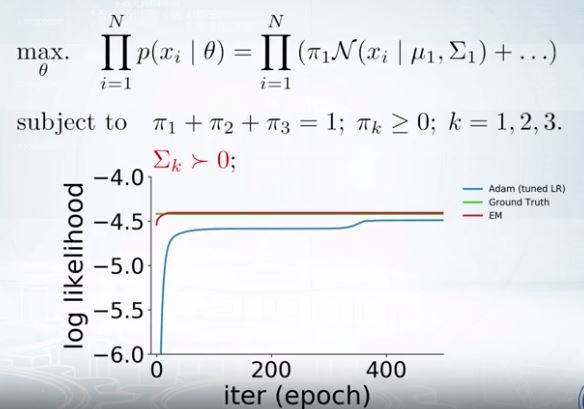
stochastic descent를 사용할 수 있는데, EM이 더 효율적이다.
여기서 Sigma는 positive definitive.
Training GMM
Introducing latent variable

각 데이터포인트가 latent varaible t의 정보를 이용하여 생성되었다고 해보자.
t는 어떤 가우시안에 속하는지에 대한 확률변수이다.
이것은 실제로 관찰되지도 못하지만, 이것은 도움이 될 수 있다.
t가 prior distribution \(\pi\)를 지니고 있다고 가정할 수 있고, 이를 이용하여 마지막 식을 만들어 낸다.
| latent variable를 marginalize하면 원래의 분포 $$p(x | \theta)$$를 얻을 수 있다. |
이는 원래의 모델과 동일한 결과를 낸다.
Expectation Maximization
만약 각 포인트에 대한 t를 잘 알고 있다면 \(\theta\)를 찾는 것은 매우 쉽다.
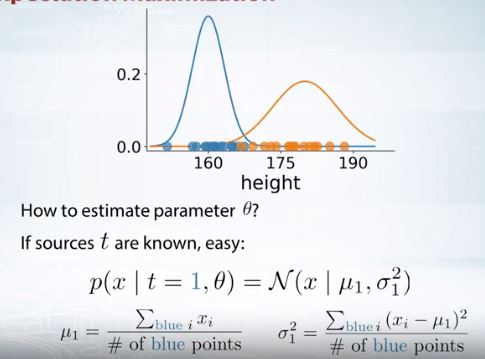
그러나 soft clustering으로 생각하면 모든 가우시안에 속해있다는 식으로 생각할 수 있다.
x가 어디에 속하는지 안다면 어떤 가우시안의 매개변수를 구하는 것은 매우 쉽다.
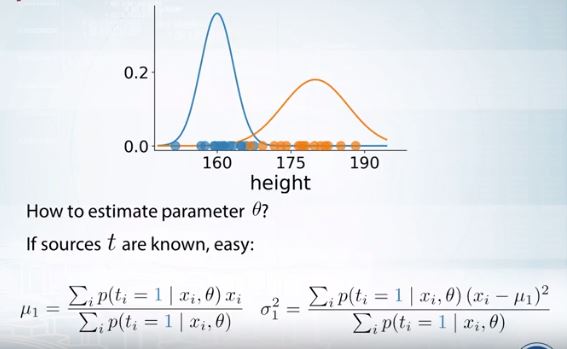
Hard이든 soft이든 어디에 속하는지, 혹은 어디에 얼마나 속하는지 안다면 매개변수를 구하는 것은 매우 쉬운 일이다.
그러나 문제는 이것이 어디에 속하는지 어떻게 아냐는 것이다. 출처를 모르는데 어떻게 매개변수를 구하나?
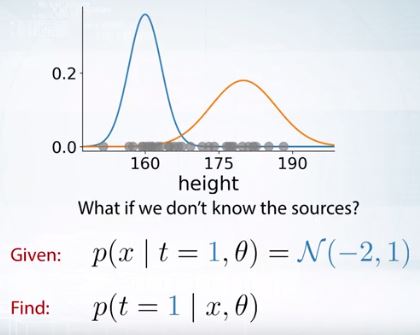
반대로 우리가 만약 매개변수인 평균과 분산을 안다면 베이즈 룰을 통해 출처를 예측하는 것은 쉽다.
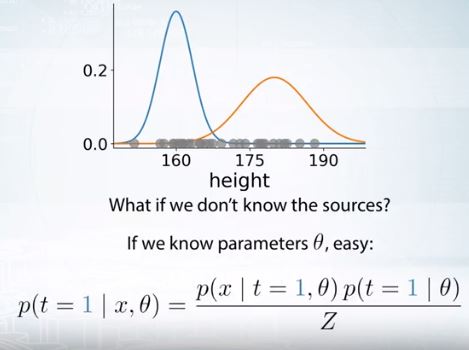
어떤 가우시안에 속할 확률은 likelihood와 prior의 곱인 joint probability에 비례한다.
soft assignment에선 정규화상수가 걱정될 수 있다. 위의 예제에서는 blue와 orange만 생각하여 더해주면 이를 통해 normalize할 수 있다.
Chicken and egg problem
이는 마치 닭이먼저냐 달걀이 먼저냐와 같은 논의이다.
- Need Gaussian parameters to estimate sources
- Need sources to estimate Gaussian parameters
EM알고리즘에선 이걸 어떻게 처리할까?
먼저 파라미터를 랜덤하게 설정하고, 두 단계를 convergence할때까지 밟는다.
충분히 길게 밟게되면 쓸만한 해를 찾게 된다.
Example of GMM training
EM Algorithm
- Start with 2 randomly placed Gaussians parameters \(\theta\)
- Until convergence repeat:
a) For each point compute \(p(t=c|x_i,\theta)\): does \(x_i\) look like it came from cluster c?
b) Update Gaussian parameters \(\theta\) to fit points assigned to them
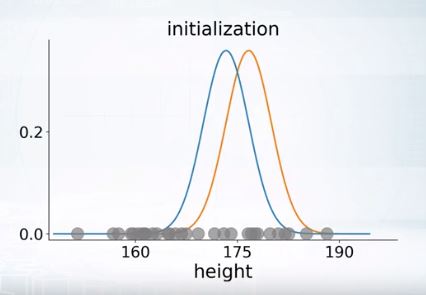
이렇게 Initialize된 것을 바탕으로 어느 가우시안에 얼마나 속하는지를 평가함.
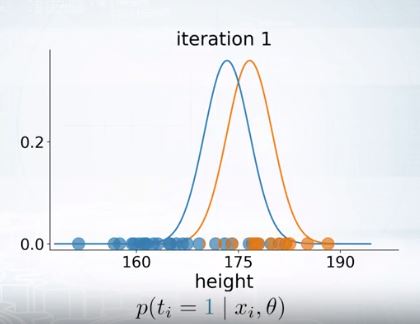
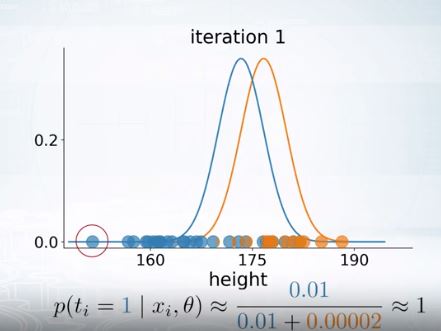
포인트에 따라 파라미터를 다시 설정하면
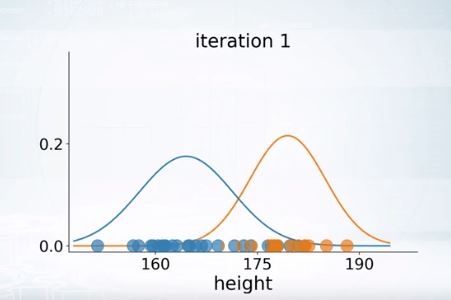
이렇게 이터레이션 하나가 끝난다.
계속하면 converge한다. 이 경우는 initial value가 잘 설정되어 converge하면서 거의 모양이 변하지 않는다.
그러나 EM은 local maxima 문제를 겪기도 한다.
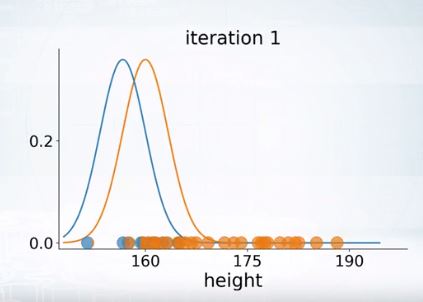
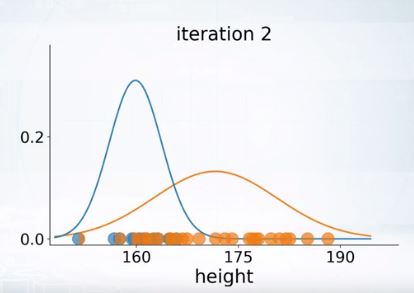
initial value를 잘못 설정하면 위와같이 좋지않은 clsutering이 된다.
이를 방지하기 위해선 여러번 시도한 것 중에 best run을 찾아야 하는데,
training set에서 최고의 log likelihood를 얻은 것이나 validation set에서 최고의 log likelihood를 얻은 것을 선정하면 된다.
Summary
- Gaussian Mixture Model is a flexible probabilistic approach to clustering problem
- Expectation Maximization algorithm can train GMM faster than Stochastic Gradient Descent and also handles complicated constraint
- Expectation Mazimization suffers from local maxima (the exact solution is NP-hard)