Jensen’s inequality & Kullback Leibler divergence
EM 알고리즘은 거의 대부분의 latent variable model을 학습시킬 수 있다.
그 전에 몇가지 수학적 도구들을 살펴보자.
Concave functions
이는 Jensen’s inequality와 연관된다.
concave의 정의는 곡선 상의 어떤 점 두개를 직선으로 그었을 때 그 구간 사이의 곡선이 전부 직선보다 커야한다는 것.
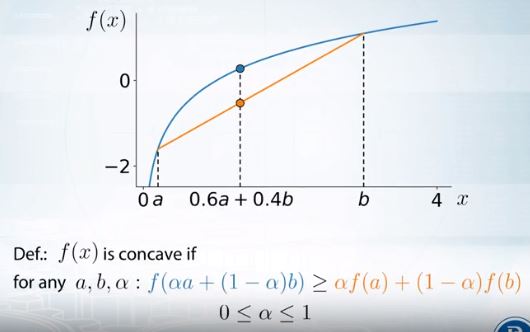
Jensen’s inequality
이는 여러개의 점으로 확장될 수 있다.

Stat110 Inequality 파트 참고
Kullback-Leibler divergence

양쪽에서 두 분포는 1 차이가 나지만 variance의 차이가 있다.
그리고 파랑과 주황의 분포보다 초록과 빨강의 분포가 더 비슷해보인다.
이러한 경우 두 분포간의 차이를 나타내기 위해 사용하는 방식이 Kullback-Leibler divergence이다.
아래의 식은 \(D_{KL}(q\|p) = E[log q(x) - log p(x)]\)
와 같이 쓸 수 있다.

KL divergence의 특징 세가지를 잘 기억하자.
KL divergence는 두 분포를 비교하기 위해 사용하는 것이다.
Expectation-Maximization Algorithm

marginal likelihood로 파라미터가 주어졌을 때의 x에 대한 확률을 구할 수 있다. 이 때 t에 대해 marginalize한다.
이는 likelihood를 maximize하는 문제가 된다.
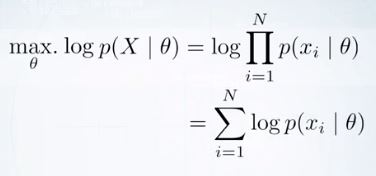
log likelihood로 product를 sum으로 바꾼다.
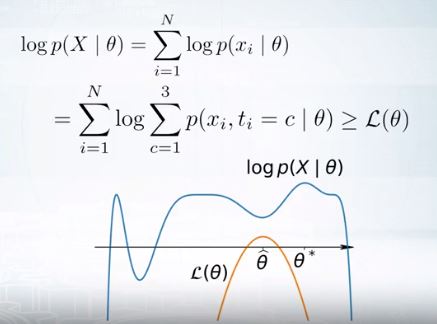
그러면 Jensen 부등식을 통해 Lower bound를 만들 수 있는데, 이 때 lower bound를 maximize하는 식으로 \(\hat{\theta}\)를 찾는다.
그러나 이것이 실제 likelihood의 maxima이지 않을 수 있다. 그림처럼 local minima에 빠져있는 경우가 있다. 이러한 지점은 approximate maximum이라고 한다.

하나의 lower bound로는 좋지 않은 결과가 나오므로 여러개의 lower bound를 두어보자. t에 대한 함수 q로 q/q를 곱하면 Jensen’s inequality에서의 계수 \(\alpha\)처럼 사용할 수 있게 된다. q는 weight이다.
이를 lower bound로 사용해보자.

제일 좋은 lower bound를 사용하면 된다.
다음으로 이를 Iterative하게 사용하는 방법을 알아보자.
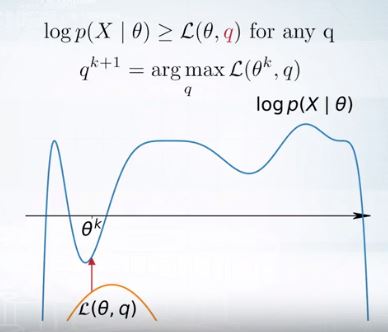
먼저 \(\theta^k\)에 대해 maximum인 lower bound를 찾는다. 그리고 이 q가 최대가 되도록 한다. 그리고 그 최대인 q를 다음 q인 \(q^{k+1}\)이 되게 한다.
이 q는 variational parameter라고 한다.
그리고 이 q가 주어졌을 때의 lower bound를 variational lower bound라고 한다.
이 q를 찾는 것은 E-step이라고 한다.
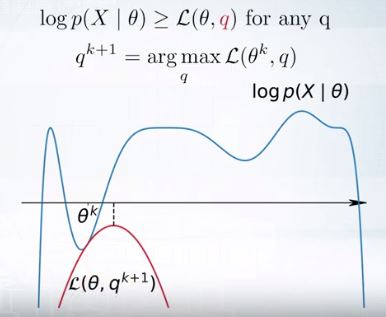
새로운 q에 대해서 최대가 되는 \(\theta^{k+1}\)을 찾는다. 이는 M-step이다.
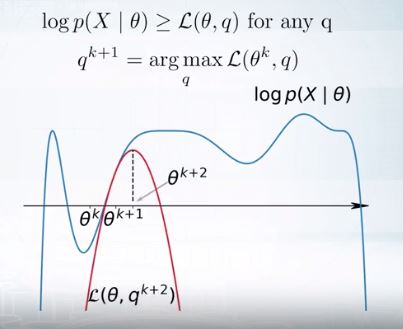
이를 계속해서 반복한다.

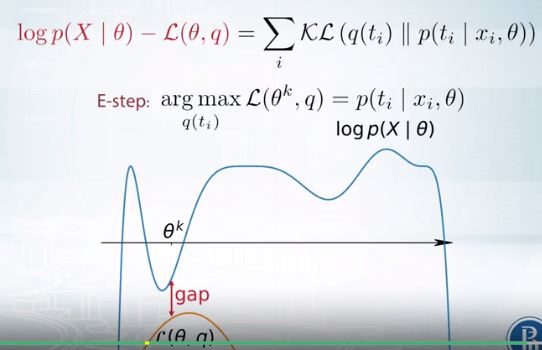
E-step details
E-step은 \(q\)에 대해 Lower bound를 최대화 하는 것이다.
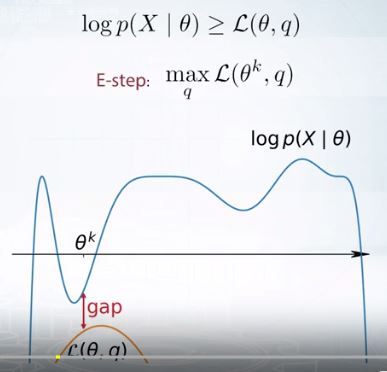
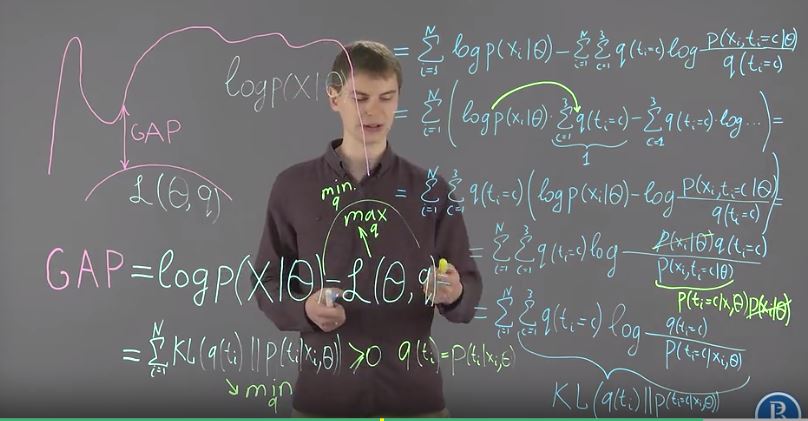
Lower bound 자체도 KL-divergence의 합인데, GAP도 정리하면 KL-divergence의 합으로 표현된다.
| 그리고 global optimum은 $$q(t_i)=p(t_i | x_i, \theta)$$일 때이다. |
즉 q가 데이터 X가 주어졌을 때 ti의 posterior distribution과 같을 때 global optimum이다.
M-step details
M-step은 \(\theta\)에 대해 Lower bound를 최대화 하는 것이다.

여기서 -sum의 경우 \(\theta\)에 대해 dependent하지 않으므로 무시해도 좋다.
그렇기 때문에 lowerbound 전체를 maximize할 필요 없이 첫번째 항만을 maximize하면 된다.
그리고 이는 concave하기 때문에 local maximum이 global maximum이다.
결국 EM algorithm은 다음 둘을 번갈아서 하는 것이다.

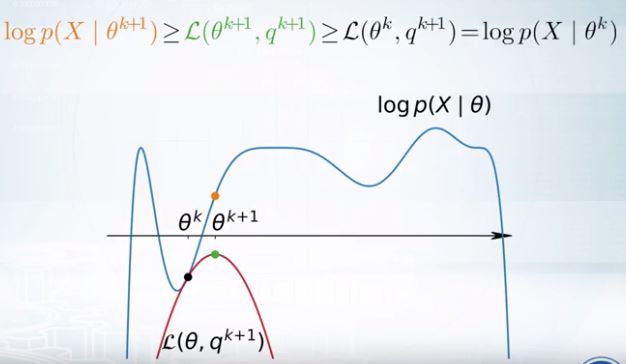
이는 local maxima에 갇힐 순 있지만 계속해서 증가하는 것은 부등식을 통해 자명해지므로 수렴한다는 것을 알 수 있다.

Example: EM for discrete mixture, E-step

1, 2, 3에 대한 히스토그램이 있다.
이 데이터는 두개의 mixture에 의해서 생성되고,
각 확률은 \(p_1, p_2\)이다.
그리고 latent variable model을 설정한다.
다음으로 변수를 initialize하고,
prior와 conditional probability를 설정할 수 있다.
여기서 얻어지는 \(q(t_i)\)는 어떤 분포 \(p_i\)가 \(x_i\)를 얼마나 잘 설명하는지에 대한 가중치이다.
이제 이를 가장 잘 설명하는 \(\alpha, \beta, \gamma\)를 찾으면 된다.
\[q(t_i=1)\] \[p(t_i=1 | x_i = 1)=1\] \[p(t_i=1 | x_i = 2)=0.5\] \[p(t_i=1 | x_i = 3)=0\]파라미터에 비추어보면 당연한것이다.
결국 q는 파라미터들에 의해 얻어지는 posterior인 것이다.
Example: EM for discrete mixture, M-step

\(\alpha, \beta, \gamma\)에 대한 최대의 log likelihood를 식으로 두고 전개하면 계산할 수 있다.
이 때 maximum을 찾기 위해 gradient=0인 지점을 찾으면 \(\alpha, \beta, \gamma\)를 찾을 수 있다.
Example: Summary of Expectation Maximization
- Latent Variable Model을 트레이닝하기 위한 방법
- Missing data를 다룰 수 있음
- Maximum Log Likelihood를 푸는건 어렵기 때문에, 간단한 Lower bound를 iteration을 통해 수렴시킨다.
- 수렴한다
- positive semi-definite한 covariance matrix와 같은 복잡한 parameter constraints를 사용할 수 있다.
- 다양한 변형방법: Variational E-step(가능한 q의 집합을 제한), Sampling on M-step
그러나 local maximum만을 찾는다는 제한이 있다.