General EM for GMM
GMM에 EM을 적용해보자.
GMM에서 파라미터 \(\theta\)에 해당하는 것은 weight인 \(\pi\), 위치인 \(\mu\), 공분산인 \(\sum\)이다.
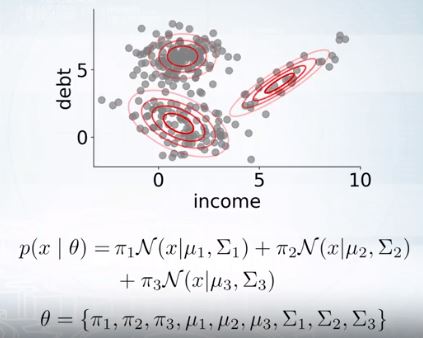


\(\mu\)와 \(\sigma\)는 위와같이 구해진다.
여기서 \(\pi\)의 constraint를 살펴보아야한다.
합이 1이되게 하는 부분에서 Normalization용으로 object의 갯수인 N을 사용한다.
가우시안의 weight가 q의 weight의 합에 비례하는것은 뭔가 직관적인것같다.
K-means from probabilistic perspective
E-step
K-means는 하나의 포인트가 하나의 클러스터에만 속한다.
이는 Hard clustering이다.


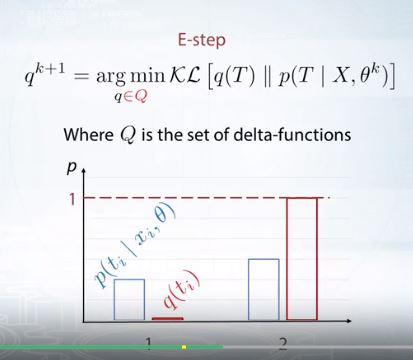
hard clustering에선 q가 그냥 제일 weight 높은거 하나에 몰빵하는 식이다.

위는 다음 문제를 푸는것과 같다.

M-step


Summary
K-means는 사실 GMM에 대한 EM과정인데,
- \(\sum_{c} = I\)인 fixed covariance를 가지고 있다.
-
단순화된 E-step을 가진다.($$p(t_i x_i,\theta)$$를 델타함수로 근사한 것이다.)
그러므로 K-means는 GMM보다 flexible하지만 빠르다.
Probabilistic PCA
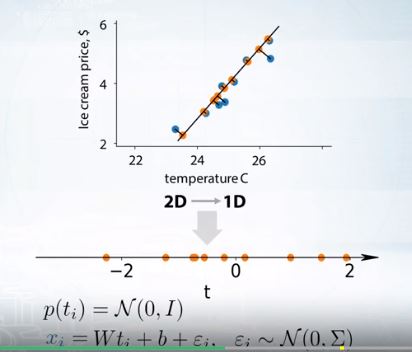
latent model을 이용해 투영과 잔차로 나타낼 수 있다.

prior가 투영된 것을 latent model으로 가우시안으로 표현하고
likelihood를 원래의 데이터를 만들어내는 가우시안으로 표현할 수 있다.
그런데 여기서 문제는 전부다 가우시안이라서 conjugate하여 latent model을 하여도 해석적으로 이를 풀 수 있게 되고, 이 때문에 원래의 PCA 공식과 똑같은 값을 얻는다는 것이다.
그래서 이러면 EM Algorithm은 필요없다.
그러나 missing values가 있다고 하면 이를 해석적으로 풀 수 없고, numerical하게, EM Algorithm을 적용할 수 있다.
EM for Probababilistic PCA

E-step은 Analytical하게 간단히 구해진다.
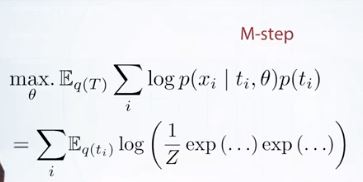
M-step에선 sum과 E를 교환하고 위와같이 구해진다. 분포가 가우시안임을 잊지말자.

그런데 상수 Z는 \(q_i\)와 전혀 dependent하지 않으므로 위와같이 쓸 수 있다. Z에 대해선 기대값을 찾을 필요가 없는 것이다.
이는 이차방정식 형태로 나타난다. Gradient를 찾자.
이제 해석적으로 이를 풀 수 있다.
Summary
Probabilistic formulation of PCA
- Allows for missing values
- Straightforward iterative scheme for large dimensionalities(이러한 iterative한 방식은 어떤 경우 original PCA보다 훨씬 효율적으로 numerical하게 계산할 수 있다.)
- Can do mixture of PPCA
- Hyperparameter tuning (number of components or choose between diagonal and full covariance)