Prerequisites
https://www.youtube.com/channel/UC7gOYDYEgXG1yIH_rc2LgOw/playlists
Optimization problems
“Translate Conceptual idea into \(P:min_{x \in D} f(x)\), which is Optimization problem”
Convex optimization에서는 P를 푸는 방법에 대해 배운다.
Examples of opt problems
- Network flow
- Regressions: least squares - \(min_{\beta} (y_i-x_i^T \beta)^2\)
- Regularized regression: lasso - \(min_{\beta} (y_i-x_i^T \beta)^2\) s.t. \(\sum \left \| \beta_j \right \| \le t\)
- Max grade s.t. \(effot \lt t\)
- Max likelihood
- SVMs
- Classification: logistic regression
…
Examples of contrary
- hypothesis testing / p-values
- boosting
- random forests
- cross-validation/bootstrap
Why?
이미 다른사람들이 \(P: min_{x \in D} f(x)\)를 푸는 법을 다 알아 냈을텐데, 왜 힘들이는가.
두가지만 말해보자면,
- 서로 다른 알고리즘은 서로다른 문제 P에 대해서 성능이 다를 수 있다.(언제나 최고인 알고리즘은 없다)
- P를 공부하는 것은 문제에 대한 통계적 과정을 이해하는데 깊은 이해를 준다.
최적화는 현재도 계속해서 발전중인 분야다. 빠르게 변화할 수 있다. 하지만 통계학과 ML에 대해 발전할 부분이 많이 남아있다.
Example: algorithms for 2d fused lasso
2d fused lasso or 2d total variation denoising:
\[\overbrace{min}_{\theta} \frac{1}{2} \sum_{i=1}^{n} (y_i - \theta_i)^2 + \lambda \sum_{(i,j) \in E} |\theta_i - \theta_j|\]
강의노트 참고
y는 [3,7] 값을 가지는 우리가 실제로 보는 Data 이미지를 벡터로 unravel한 것이다.
실제 이미지는 구간별 상수(piecewise constant)를 가진다.
이미지의 y가 자주 바뀌지 않는다.
우리가 보는 데이터는 노이즈가 굉장히 심하다. 더이상 piecewise const하지않다.
우린 데이터 엔트리 \(y_i\)에 대해 \(\theta\) 하나만을 가지고 있다. 이 역시 이미지를 벡터로 unravel한것이다.
첫번째 항은 least square loss이고, theta가 원래 데이터와 너무 달라지지 않도록 하는 것이다.
두번째 항은 페널티인데, \(\lambda\)는 하이퍼파라미터인데 25정도로 크게 설정했다고 한다. 그리고 \(i,j\)는 모든 인접한 theta이다. E는 edge의 집합이다. 인접한 데이터가 서로 다르면 페널티도 커진다. \(\lambda\)를 크게 설정하면 i,j가 많은 곳에서 완전히 똑같아진다. 결국 인접 픽셀을 똑같은 색으로 만드는 역할을 한다. 람다가 커질수록 이미지가 piecewise constant해진다. 무한하게 크다면 이미지 전체가 Y의 평균색으로 변할것이다.
…
서로 다른 알고리즘들을 통해서 푼결과들에 대한 얘기.
의미
여기서 alternating direction method of multiplier(ADMM)이 다른 메소드들을 발라버렸다.
그러면 ADMM이 최고의 알고리즘인가?
그렇지않다.
다른 상황이었다면 다른 알고리즘이 더 좋았을 수도 있다.
2d fussed lasso problem:
- Specialized ADMM: fast(structured subproblems)
- Proximal gradient: slow(poor conditioning)
- Coordinate descent: slow(large active set)
Example: testing changepoints from the 1d fused lasso
조교중 한명이 제안한것이라고 한다.
1d fussed lasso or 1d total variation desnoising
2d 벡터로 unravel하는 것이 아니라 1차원 직선으로 만들었다. 그리고 y의 평균은 piecewise constant할것이다.
\[\overbrace{min}_{\theta} \frac{1}{2} \sum_{i=1}^{n} (y_i - \theta_i)^2 + \sum_{i=1}^{n-1} |\theta_i - \theta_{i+1}|\]여기서는 직선이므로 i와 i+1만을 보면 된다.
\(\lambda\)가 크면 Y 전체의 평균을 얻는다. 모든 \(\theta\)는 \(\bar{y}\)와 같게된다.
\(\lambda\)가 줄어들면서 piece가 늘어난다. piece가 변하는 부분을 chagnepoint라고 한다.
강의노트 참고
나중에 다시 와서 이해해야할듯..
Central concept: convexity
역사적으로 linear program이 최적화의 중심이었다.
초창기에는, linear와 nonlinear의 구분이 최적화에서 중요한 것으로 보여졌다. 그러나 몇몇 nonlinear 문제들은 다른 문제보다 훨씬 풀기 어려웠다.
이제는 convex와 nonconvex로 구분하는 것이 더 중요한 것으로 인식된다.
Convex problem과 Nonconvex problem은 매우 다르다.
일반적인 convex에 대한 도구들은 충분한 시간만 있으면 결국 작동한다.
KKT-condition과 duality는 해의 특성을 이해하는데 최고라고 할 수 있다.
그러나 non convex problem은 어떤 특정한 문제를 푸는 방법을 발견할 수 있을진 모르지만, 문제를 살짝 바꾸기만 하면 풀기 매우 어려워 지는 경우가 있다. 완전히 다른 알고리즘을 만들어내야 할 수도 있다.
Supplementary
Convex sets and functions

Convex set
C의 두 원소에 대해 둘 사이를 잇는 직선을 연결했을 때, 그 직선상의 모든 점들이 C에 포함되어야한다.
노트에 증명과정이있다.
Convex funciton
\(f:R^n \rightarrow R\) 인 함수인데,
함수 상의 두 점에 대해 둘 사이를 잇는 직선 상의 모든 점이 함수보다 커야한다.
그림에서 dom은 domain이라는뜻
이 둘은 서로 다른것이 아니다.
Convex optimization problems

f(x)를 최소화화는데, 부등식과 등식에 의해 종속된 상태에서 하는것. 어떠한 최적화 문제라도 이렇게 씌여질 수 있다.
min 아래에 있는 D는 common domain이며 \(g_i,h_j\)가 여기 속한다.
이 모든 함수가 정의된 유한한 공간이다.
이것이 최적화 문제이고.
Convex 최적화는:
이중 \(f\), criterion이라고 부르고, 부등식의 \(g_i\)는 convex function이어야하고, 등식의 \(h_j\)는 affine function이어야 한다.
\[h_j(x)=a_j^T x + b_j, j=1,...p\]여기서 \(a_j\)는 벡터이고 \(b_j\)는 스칼라이다.
affine은 linear와 비슷하게 보이는데, 가끔 혼용해서 쓸때도 있다. 그런데 affine은 \(b_j\) offset이 있다. linear에는 offset이없다.
{kind=link}
convex function은 convex domain을 가져야한다. \(h\)의 도메인은 \(R^n\) 전부이고 \(g,f\)는 convex domain을 가져야한다.
그리고 이 convex set의 intersection이다.
Local minima are global minima

“컨벡스 최적화에선 지역최소값이 전역최소값이다.”
컨벡스 최적화의 매우 중요한 특성이다.
만약 x is feasible(x가 common domain에 있고 모든 constraints를 만족한다면), f를 지역최소로 만든다면,
즉, 모든 근처(반경 \(\rho\))의 feasible y에 대해 \(f(x) \le f(y)\)라면,
모든 feasible y에 대해 \(f(x) \le f(y)\)
증명
contradiction을 이용해 증명하기.
| suppose \(\exists z \in D\), feasible s.t. $$f(z) < f(x), ( | z-x | _2 > \rho)$$ |
x와 z를 잇는 직선을 그엇을 때,
두가지를 만족해야한다.
- \(y \in D\)?
- \(y\) feasible?
첫번째 조건은 만족한다. D가 convex하기 때문이다.
두번째 조건을 살펴보자.
\[g_i(y)=g_i(t_x + (1-t)z) \le tg_i(x)+(1-t)g_i(z) \le 0\]feasible하다. 모든 constraints를 만족한다.
\[h_i(y)=h_i(t_x + (1-t)z)=0\]t가 충분히 클 때, (1에 가깝지만, 1보단 작을 때)
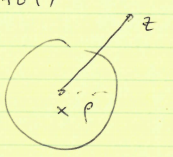
그런데 \(f(z)\)가 \(f(x)\)보다 작으므로,
\[tf(x)+(1-t)f(z) \lt f(x)\] \[f(y) \lt f(x)\]\(\rho\) 공모양 반경 안에 있는데도 이것이 성립할 순 없다.
Contradiction!
강의 노트 마지막 참고