Discrete vs Continuous, the Uniform

CDF를 미분하면 PDF가 된다.
기대값도 이산합이 아니라 적분으로 계산한다.
균등분포는 이산에서 조약돌 세계의 모든 조약돌이 같은 무게인 것과 비슷하다.
연속에서 구간내 모든 지점의 밀도가 동일한 것.



Universality of Uniform Distribution
모의실험시 유용하게 사용.


Independence of random variable
이산에서는
\[P(X_1 = x_1,...,X_n=x_n)=P(X_1=x_1) \cdot ... \cdot P(X_n = x_n)\]Joint PMF를 사용했지만,
연속에서는
\[P(X_1 \le x_1,...,X_n \le x_n)=P(X_1 \le x_1) \cdot ... \cdot P(X_n \le x_n)\]for all \(x_1,...,x_n\)
이런 Joint CDF가 나타난다. CDF에서는 이것이 성립하면 확률변수가 독립적이라고 한다.
사건의 독립성보다 덜 복잡해 보인다. 사건의 독립성에서는 세 사건의 독립성을 보기위해 두개 끼리의 독립성(pairwise)과 세개 전부의 독립성(mutual)까지 다 보아야 했다.
그런데 자세히 보면 모든 \(x_1,...,x_n\) 에 대해 성립해야 한다는 것이 중요하다.
증명은 별로 어렵지 않다고 한다.
이것의 의미는 이 여러 사건들 중 몇개가 일어나는 것을 안다고 해도 다른 사건의 실행 여부와 관계가 없다는 뜻이다.
그래서 pairwise보다 훨씬 강력하고 까다롭다.
이러한 완전한 독립성(Full independence)은 어떤 사건의 실행 여부를 알아도 나머지에 대해 아무것도 모르는 것이다.
Normal Distribution
\[N(\mu, \sigma^2)\]Standard Normal Distribution
\[Z \sim N(0,1)\]Closed form이라 유도할 수 없다.
\[\int_{-\infty}^{\infty}e^{-z^2}/2 dz \int_{-\infty}^{\infty} e^{z^2}/2 dz\]이렇게 제곱하면
\[\int_{-\infty}^{\infty}e^{-x^2/2}dx\int_{-\infty}^{\infty} e^{-y^2/2}dy \\\\ =\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} e^{-(x^2+y^2)/2}dxdy = \int_{2 \pi}^{0} \int_{0}^{\infty} e^{-r^2/2}r dr d \theta\] \[=\int_{0}^{2 \pi} \int_{0}^{\infty}e^{-u}dud \theta = 2 \pi\] \[\therefore \int_{-\infty}^{\infty}e^{-z^2/2}dz = \sqrt{2 \pi}\] \[c= \frac{1}{\sqrt{2 \pi}}\]파이가 나타나는 것은 중간에 \((x^2 + y^2)\) 꼴이 지수에 나타나기 때문.
평균
\[Z \sim N(0,1)\] \[E(Z)=0\]기함수다.
분산
\[Var(Z)=E(Z^2)-\{E(Z)\}^2=E(Z^2)\] \[=\frac{1}{\sqrt{2 \pi}}\int_{-\infty}^{\infty} z^2 e^{-z^2/2}dz = \frac{2}{\sqrt{2 \pi}}\int_{0}^{\infty} z^2 e^{-z^2/2}dz\] \[u=z,dv=ze^{-z^2/2}\] \[du=dz,v=-e^{-z^2/2}\] \[=\frac{2}{\sqrt{2 \pi}} [uv]_0^{\infty} + \int_0^{\infty}e^{-z^2/2}dz=1\] \[Var(Z)=E(Z^2)-{E(Z)}^2 = E(Z^2)=1\]CDF
\[\Phi (z)=\frac{1}{\sqrt{2 \pi}} \int _{-\infty}^{z} e^{-t^2 / 2} dt\]이를 계산하기는 힘들다.
정규분포의 특성: 대칭
\(Z \sim N(0,1)\) 이고 CDF \(\Phi\) 를 가질 때,
\[E(Z)=0\] \[E(Z^2)=Var(Z)=1\] \[E(Z^3)=0\]홀수차 적률은 기함수이기 때문.
정규분포의 대칭성으로 인해 \(-Z \sim N(0,1)\)
일반정규분포
\(X=\mu + \sigma Z\) 일 때,
\(\mu \in R\)(평균, 위치(location) 만큼 이동)
\(\sigma >0\)(표준편차, 크기(scale) 만큼 스케일링)
\[E(X)= \mu\] \[Var(X)= \sigma^2Var(Z)=\sigma^2\]분산의 특성
\[Var(X)=E(X^2)-\{E(X)\}^2\] \[Var(X_c)=Var(X)\] \[Var(cX)=c^2Var(X)\] \[Var(X+Y) \ne Var(X) + Var(Y)\]마지막은 X,Y가 서로 독립일 때만 성립하는 식.
표준화
\[Z=\frac{X-\mu}{\sigma}\] \[X \sim N(\mu, \sigma^2)\]CDF
\[P(X \le x )=P(\frac{X-\mu}{\sigma} \lt \frac{x-\mu}{\sigma})\] \[=\Phi(\frac{X-\mu}{\sigma})\]j=1,2,… 에 대하여 \(X_j \sim N(\mu_j, \sigma_j^2)\) 이고 서로 독립일 때,
\[X_1+X_2 \sim N(\mu_1+\mu_2, \sigma_1^2 + \sigma_2^2)\] \[X_1-X_2 \sim N(\mu_1-\mu_2, \sigma_1^2 + \sigma_2^2)\]68-95-99.7% Rule
\[P(|X-\mu| \le \sigma) \approx 0.68\] \[P(|X-\mu| \le 2\sigma) \approx 0.95\] \[P(|X-\mu| \le 3\sigma) \approx 0.997\]LOTUS
\[E(g(x))=\sum_x g(x) P(X=x)\]2X의 기댓값을 구할 때
\[\sum_x 2x P(X=x)\]를 구하면 된다.
\(X^2\)의 기댓값을 구할 때
\[\sum_x x^2 P(X=x)\]를 구하면 된다.
많은 사람들이 이것을 아무렇지 않게 사용하는데, 실제로는 까다로운 문제이다.
\(\sum_x \sum_{S:X(s)=x} g(X(s))P({s}) =\)\sum_x \sum_{S:X(s)=x} P({s}) \
=\sum_x g(x) P(X=x)
$$
이렇게 생각하면 이산에 대해서 증명할 수 있고, 아무 생각없이 사용해도 괜찮다는 것을 알 수 있다.
이를 Law of the Unconscious Statistician 이라고 한다.
포아송 분포의 평균과 분산
LOTUS로 분산을 구해보자
평균
\[E(X)=\sum_{x=0}^{\infty} x \frac{\lambda^x e^{-\lambda}}{x!}=\lambda\]분산
\[E(X^2)=\sum_{k=0}^{\infty} k^2 e^{-\lambda} \lambda^{k} / k!\]아래 식을 미분하면,
\[\sum_{k=0}^{\infty} \frac{\lambda^k}{k!}=e^{\lambda}\]다음이 나온다.
\[\lambda \sum_{k=1}^{\infty} \frac{k \lambda^{k-1}}{k!}=\sum_{k=1}^{\infty}\frac{k \lambda^k}{k!} = \lambda e^{\lambda}\]이를 또 미분하면,
\[\sum_{k=0}^{\infty}\frac{k^2 \lambda^{k-1}}{k!}=\lambda e^{\lambda} + e^{\lambda} = e^{\lambda}(\lambda+1)\]이를 대입하면.
\[=e^{-\lambda}e^{\lambda}(\lambda+1)\lambda\] \[=\lambda^2+\lambda\] \[Var(X)=E(X^2)=\{E(X)\}^2 \\\\ =\lambda^2 + \lambda - \lambda^2 = \lambda\]이항분포의 분산
\[X=I_1 + ... + X_n, I_j \sim^{iid} Bern(p)\] \[X^2=I_1^2 + ... + I_n^2 + 2I_1I_2+...2I_{n-1}I_n\] \[E(X^2) = nE(I_1^2)+2\binom{n}{2} E(I_1I_2)\] \[=np+n(n-1)p^2\] \[=np+n^2p^2 - np^2\] \[Var(X)=np(1-p)=npq\]Exponential Distribution
책이 출간되기까지의 기간이라든가, 전구가 고장나기까지의 시간.
어떤 일이 일어나기까지의 대기시간으로 해석할 수 있다.
\[Expo(\lambda)\]모수 \(\lambda\) 는 rate parameter로 속도를 나타낸다.
조건확인: 적분시 1
CDF
\[F(x)= \int_0^x \lambda e^{-\lambda t}dt \\\\ =1-e^{-\lambda x}, x>0\]기댓값과 분산
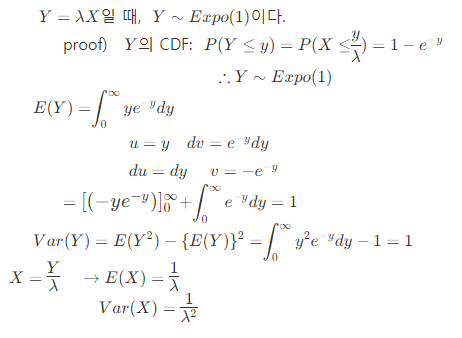
무기억성(memoryless property)
이산확률분포: 기하분포
연속확률분포: 지수분포
이 둘은 각각의 분포에서 무기억성을 지닌 유일한 분포이다.
무기억성 그자체가 기하분포와 지수함수이다.